MongoDB Vector Search у Laravel: як знаходити те, що не піддається запитам
Прості пошукові запити до бази, що покладаються лише на ключові слова, часто не дають користувачам корисних результатів: вони не враховують синоніми, сленг і тонкощі релевантності. На великих наборах даних такі запити також можуть працювати повільно через неефективні методи індексації. Як наслідок, користувач отримує нечіткий або нерелевантний список результатів і гірший досвід взаємодії.
Векторний пошук принципово кращий за базові запити по ключових словах, бо працює з семантичним змістом, а не з точними збігами тексту, і при цьому спроєктований для масштабування.
Повне пояснення векторного пошуку не входить у рамки цієї статті, але коротко: векторний пошук використовує числові представлення — вектори (embeddings) — щоб знаходити об’єкти, семантично схожі на запит, тобто за змістом, а не за ключовими словами.
Тяжку роботу з побудови щільних багатовимірних векторів з тексту, зображень чи інших даних виконують готові embedding-моделі. Векторний пошук порівнює відстані або схожість між вектором запиту й векторами в базі, швидко повертаючи найбільш релевантні елементи.
Якщо хочете заглибитись, перегляньте наші відео про vectors and embedding fundamentals і про future of data querying, або почитайте детальніше в ресурсах MongoDB: explanation of vector search.
# Laravel vector search implementation
У цій статті ми використаємо репозиторій на GitHub, щоб показати, як працює MongoDB Vector Search у Laravel. Я створив тег, бо репозиторій буде оновлюватись.
README.md в репозиторії містить додаткові відомості і побудований за логікою цього туторіалу: кожен розділ пояснює «чому» для вибору конфігурацій, наводить приклади команд з очікуваним результатом та має розділ з вирішенням проблем.
# Prerequisites to run the repo
- Базове розуміння векторного пошуку
- Запустити безкоштовний кластер MongoDB Atlas з завантаженою базою mflix_sample
- Ось інструкція, how to start a free cluster (вкладка "Atlas UI") і як завантажити sample databases.
- Безкоштовний ключ API Voyage AI
- Функціональне середовище розробки PHP/Laravel. Рекомендуємо нашу готову контейнерну конфігурацію в GitHub Codespaces (безкоштовно для індивідуальних акаунтів).
Voyage AI нещодавно була acquired компанією MongoDB. Її моделі показали відмінні результати в бенчмарках, наприклад на Hugging Face MTEB Leaderboard. При цьому MongoDB Vector Search сумісний майже з усіма embedding-моделями на ринку, тож у вас є вибір залежно від кейсу.
# Connect the Laravel app to the MongoDB database
Якщо ви ще не підключали MongoDB до Laravel, у нас є детальніший туторіал: how to build a back-end service with Laravel and MongoDB. Тут ми зосередимося лише на ключових кроках для використання MongoDB Vector Search у Laravel.
Припустимо, ваш кластер MongoDB Atlas запущено і ви завантажили sample data, зокрема базу sample_mflix, яку будемо використовувати. Для цього можна скористатися GUI в MongoDB Atlas (Database > Clusters > Browse Collections) або застосунком MongoDB Compass, який інколи зручніший і швидший у роботі.
У sample_mflix є дві колекції фільмів: "movies" і "embedded_movies." Ми працюватимемо з "movies", оскільки вона не містить embeddings — наш Laravel-застосунок їх створить.
# Connect to the database
За репозиторієм спочатку підключимося до MongoDB.
Доступ по мережі кластера: переконайтеся, що ваша поточна IP-адреса внесена до білого списку кластера. Якщо ви на публічному Wi‑Fi (готель, аеропорт тощо), можливо, доведеться тимчасово дозволити доступ для всіх IP — але це небезпечно. Дотримуйтесь інструкцій у документації (перейдіть до "Add IP Access List Entries" і оберіть вкладку "Atlas GUI").
Підключення з Laravel: створіть файл .env на основі .env.example і знайдіть рядок DB_CONNECTION=mongodb. Нижче оновіть DB_DSN фактичним рядком підключення до вашого кластера з логіном і паролем. Ось тут показано, how to get the connection string in Atlas (перейдіть до сторінки Clusters у вашому проєкті).
У нашому Codespaces-середовищі при старті виконуються три команди нижче. Якщо ви налаштовуєте локально, не забудьте ініціалізувати репозиторій тими ж командами:
# create a new .env file
cp .env.example .env
# download libraries required by our app
composer install
# generate the keys for this app
php artisan key:generateУ .env замініть приклад DB_DSN на свій рядок підключення до MongoDB. Також додайте API-ключ Voyage AI.
Зауважте, що завдяки гнучкості схеми MongoDB нам поки не потрібні міграції, тож виконувати "php artisan migrate" не потрібно. Коли дані підготовлено, запустіть застосунок. Локально він доступний за http://localhost:8000, але в залежності від налаштувань PHP/Laravel URL може відрізнятись — підлаштуйте приклади нижче під свою конфігурацію.
У Codespaces URL дивіться, підводячи курсор до іконки "globe" у вкладці Ports.
 Ми будемо робити кілька API-ендпоінтів, тому в CodeSpaces порт 80 відкривають як "public" для зручності. Якщо з’явиться попередження, натисніть Continue.
Ми будемо робити кілька API-ендпоінтів, тому в CodeSpaces порт 80 відкривають як "public" для зручності. Якщо з’явиться попередження, натисніть Continue.
php artisan serveУ проєкті є кілька API-ендпоінтів для тестування додатка і підключення до MongoDB.
Пам’ятайте, у Codespaces формат URL такий: {friendly-name}-{random-hash}-{port}.app.github.dev, його можна отримати у вкладці Ports.
# returns {"response":"hello world"} if the app is up and running
curl http://localhost:8000/api/hello
# returns {"status":"success","connection":"MongoDB connection successful"...
curl http://localhost:8000/api/mongodb-testЯкщо обидва виклики повертають успіх, підключення працює і можна переходити далі: до використання Vector Search!
# 3 steps to your MongoDB Vector Search in Laravel
Якщо ваші дані вже в MongoDB, виконати векторний пошук можна у три кроки — ми детально покажемо їх нижче.
# Step 1: Generate vector embeddings for your data
Спочатку потрібно створити вектори. Ми використовуємо embedding-модель Voyage AI й генеруємо embeddings через їхній API.
Доступ до Voyage AI реалізовано як сервіс у app/Services/VoyageAIService.php, а найбільш цікава функція — generateEmbeddings(), яка приймає масив текстів і повертає векторні представлення цих текстів.
Сервіс робить REST-запит у makeRequest(). Якщо запит успішний, Voyage AI повертає для кожної точки:
- вектор (embedding)
- назву моделі embedding
- кількість вимірів
- кількість токенів, використаних моделлю
// makes a request to the external vector embedding model
$response = $this->makeRequest($texts);
if ($response['success']) {
$embeddings = $response['data']['data'] ?? [];
return [
'success' => true,
'embeddings' => $embeddings,
'count' => count($embeddings),
'usage' => $response['data']['usage'] ?? null
];
}
return $response;Вектори для записів у базі зазвичай створюють рідко: при виборі моделі, коли дані змінилися, або при переході на іншу модель. У проєкті додано консольну команду в app/Console/Commands/GenerateEmbeddings. Там же є команда для видалення embeddings.
З терміналу згенерувати embeddings можна так:
php artisan embeddings:generateПісля виконання перевірте документи в MongoDB Atlas — у кожному має з’явитися поле "embedding" з масивом з 512 чисел. Це вектор документа — тепер документи готові до індексації.
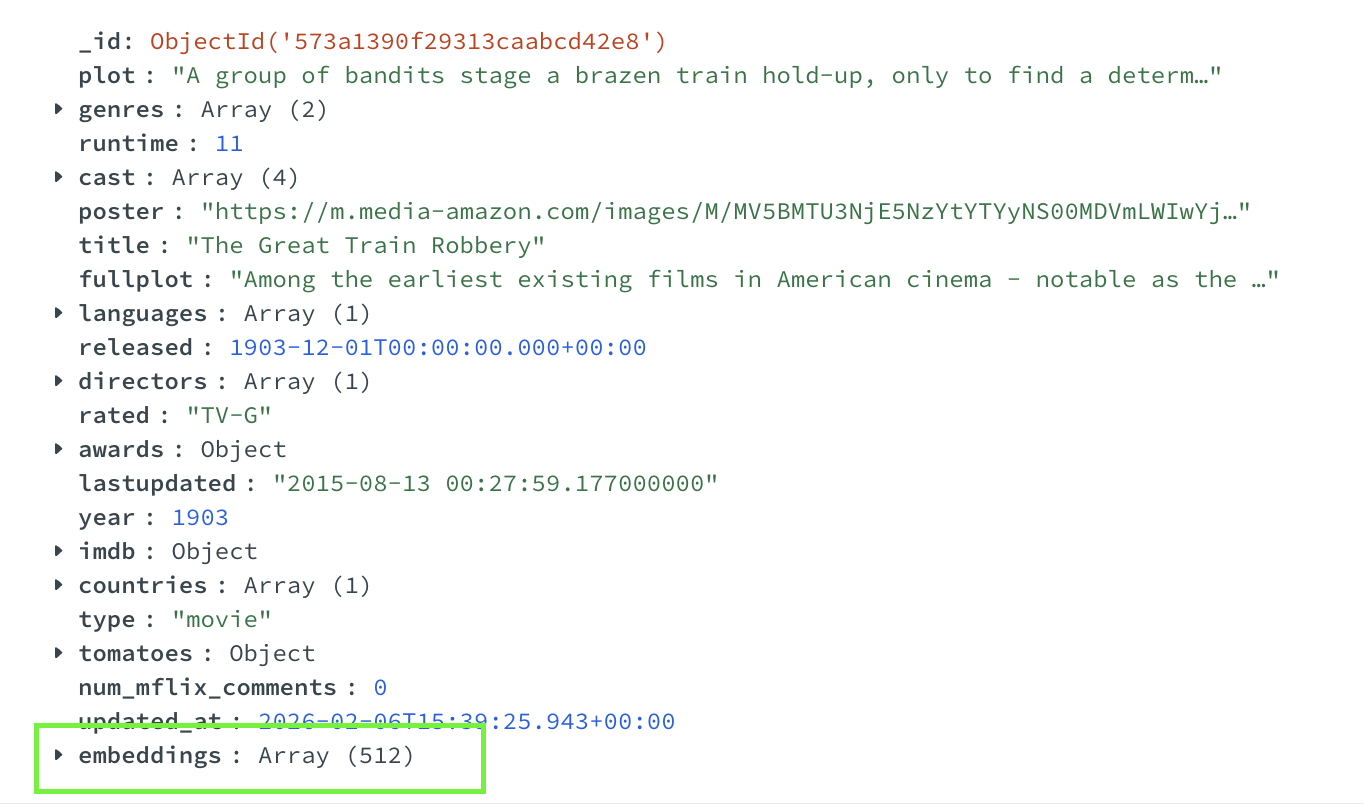 Примітка: за замовчуванням команда створює не більше 100 embeddings, щоб уникнути надмірного використання токенів на великих наборах даних. Якщо хочете експериментувати — вимкніть обмеження або підвищте значення.
Примітка: за замовчуванням команда створює не більше 100 embeddings, щоб уникнути надмірного використання токенів на великих наборах даних. Якщо хочете експериментувати — вимкніть обмеження або підвищте значення.
# Step 2: Create a vector index
Для векторного пошуку потрібен індекс — векторний індекс. У коді треба вказати три ключові параметри:
- path: ім'я поля з вектором
- numDimensions: кількість вимірів (довжина вектора)
- similarity: функція схожості для обчислення відстані
path ви задаєте як розробник — поле можна назвати як завгодно. numDimensions і similarity зазвичай вказують творці embedding-моделі — перевірте їх у документації. Ми використовуємо Voyage AI voyage-3-lite model, де вказано 512 вимірів.
Створити векторний індекс можна CLI-командою, реалізованою в /app/Console/Commands/CreateVectorIndex.php через функцію createSearchIndex().
$connection = DB::connection('mongodb');
$collection = $connection->getCollection($collectionName);
// ...
$result = $collection->createSearchIndex(
[
'fields' => [
[
'type' => 'vector',
'path' => config('vector.field_path'),
'numDimensions' => $vectorDimensions,
'similarity' => $vectorSimilarity
]
]
],
[
'name' => $indexName,
'type' => 'vectorSearch'
]
);php artisan vector:create-indexЯкщо індекс уже існує, його можна видалити й створити заново:
php artisan vector:create-index --forceПісля цього перевірте, що індекс створено і він готовий до роботи. В нашому репозиторії початкове індексування майже миттєве через 100 векторів, але в базі з кількома тисячами векторів побудова індексу займе кілька секунд і може лінійно масштабуватись. Ми показуємо приклад на безкоштовному інстансі, але для продакшну є способи масштабувати, наприклад за допомогою Search Nodes.
Також у проєкті є команда для перевірки індекса: /app/Console/Commands/CheckVectorIndex.php, яка перераховує всі індекси колекції і шукає індекс за іменем.
$indexes = iterator_to_array($collection->listSearchIndexes());
// Look for the specific vector index
$vectorIndex = null;
foreach ($indexes as $index) {
if ($index['name'] === $indexName) {
$vectorIndex = $index;
break;
}
}php artisan vector:check-indexЧому це важливо: якщо виконати запит векторного пошуку без створення індексу, помилки ви не отримаєте — API поверне 200 OK, але масив результатів буде порожнім. Це може ввести в оману нових розробників.
Альтернативно, індекс можна перевірити в Atlas GUI: зайдіть у колекцію "movies" (Database > Clusters > Browse Collections), оберіть "sample_mflix.movies" і вкладку "Search Indexes" — індекс повинен бути позначений як "ready".
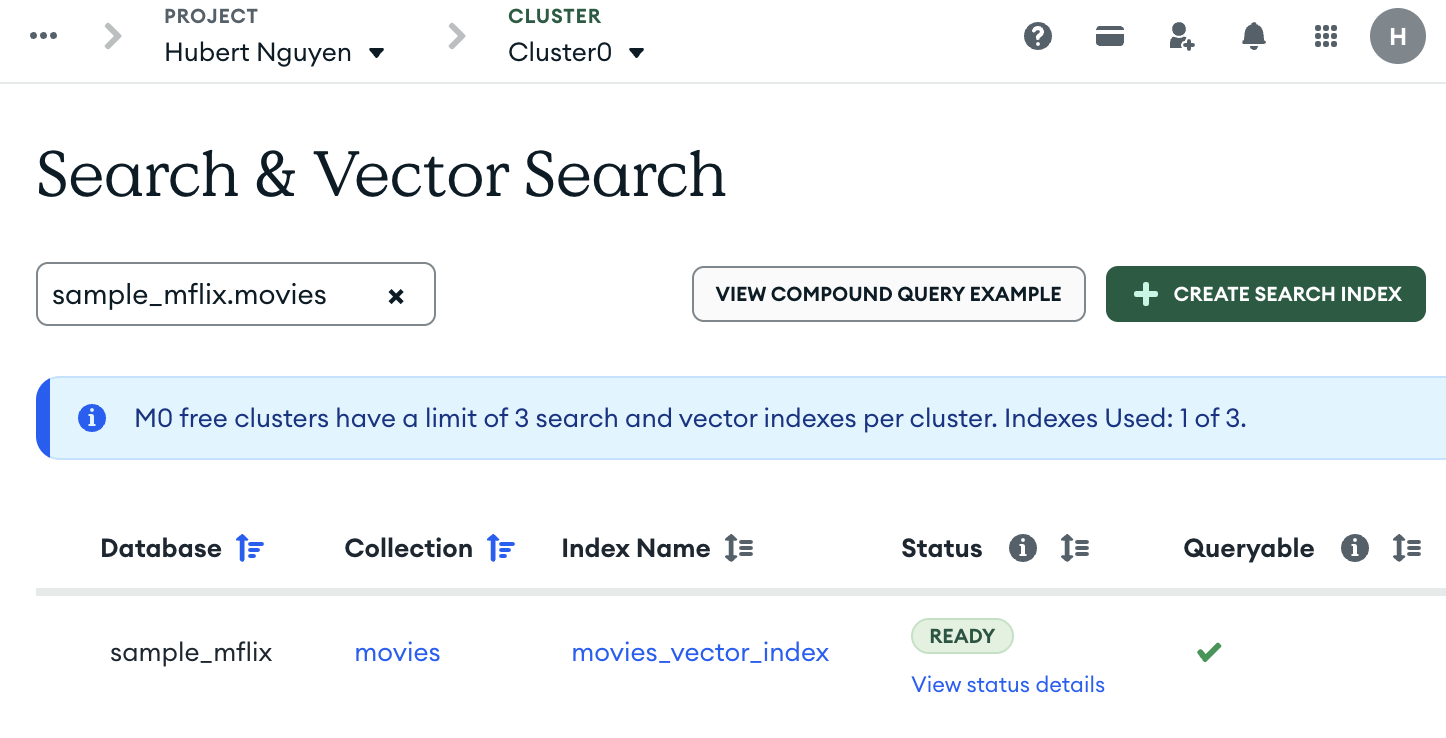
# Step 3: Perform a query
Коли векторний індекс готовий, залишилось запустити пошуковий запит. Потрібно отримати текстовий запит від користувача — для цього в проєкті є ендпоінт /api/movie-search-vector.
Ключові частини коду: генерування embedding для текстового запиту і сам векторний пошук:
// $query is the user text input
// $result is a multi-dimensions vector
$result = $voyageAI->generateEmbeddings([$query]);
if (!$result['success']) {
return response()->json([
'error' => 'Failed to generate query embedding',
'message' => $result['error']
], 500);
}
// Voyage AI returns an array of vectors
// because we use a batch embedding function
$queryVector = $result['embeddings'][0]['embedding'];
// Perform vector search using Eloquent
$results = Movie::vectorSearch(
index: config('vector.index.name'),
path: config('vector.field_path'),
queryVector: $queryVector,
limit: config('vector.search.limit'), // # of ranked results returned
numCandidates: config('vector.search.num_candidates')
);MongoDB для векторного пошуку використовує два параметри, що працюють разом: numCandidates визначає, скільки приблизних відповідностей (пул кандидатів) буде розглянуто під час обходу структури HNSW у пам’яті. Limit контролює, скільки кінцевих результатів повернути користувачу. Рекомендоване мінімальне співвідношення — 20:1 — тобто, щоб отримати 10 результатів (limit: 10), слід шукати серед ~200 кандидатів (numCandidates: 200).
Ендпоінт приймає рядок у тілі запиту; приклад з CURL:
curl -X POST http://localhost:8000/api/movie-search-vector \
-H "Content-Type: application/json" \
-d '{"query": "outlaws on the run from law enforcement"}'Відповідь може виглядати так. Ми повертаємо кілька полів (title, plot), щоб легше оцінити релевантність:
{
"query": "outlaws on the run from law enforcement",
"results": [
{
"_id": {"$oid": "573a1390f29313caabcd42e8"},
"title": "The Great Train Robbery",
"plot": "A group of bandits stage a brazen train hold-up...",
"score": 0.8234567
}
],
"count": 10,
"embedding_model": "voyage-3-lite",
"vector_dimensions": 512
}Поле "score" — корисна метадані від механізму векторного пошуку, що показує ступінь релевантності результату.
Векторний пошук завжди повертає найкращі математичні збіги за оцінкою схожості, навіть якщо найближчий результат концептуально не відповідає запиту. Дуже високий або дуже низький score у різних метриках підкаже, що знайдений елемент, ймовірно, не є хорошим співпадінням, хоч і був «найближчим» чисельно.
Тепер, коли векторний пошук працює, спробуйте інші запити. Пам’ятайте: векторний пошук знаходить за сенсом — не обов’язково потрібно знати точні ключові слова в документах.
Спробуйте, наприклад:
- "prehistoric creature comes alive"
- "rags to riches criminal empire"
- "sacrifice for a greater cause"
# Use cases
MongoDB Vector Search дає архітектурний шар для сучасних інтелектуальних додатків на Laravel. Він замінює нестабільні або повільні текстові/regex-запити й складні fuzzy-пакети на спеціалізований пошук, який треба лише налаштувати і підтримувати.
Відправляючи дані до embedding-сервісу і зберігаючи вектори, ви одразу отримуєте можливості, які раніше були або неможливими, або повільними: семантичний пошук по мільйонах записів, контекстно-залежне витягування для чат‑ботів (RAG) і персоналізовані рекомендації в реальному часі — усе через прості запити Eloquent.
Векторний пошук корисний для документного пошуку, мультимодального пошуку (текст/зображення/відео), рекомендацій ("more like this"), пошуку схожих подій у логах чи телеметрії й інших сценаріїв.
# Common questions
# What happens if the model is updated, or if I change the embedding model?
Якщо ви змінюєте модель embeddings, зазвичай потрібно згенерувати вектори заново для всіх даних. Навіть невеликі зміни моделі можуть зсунути векторний простір і вплинути на результати. Часто під час переходу тримають дві версії embeddings і відповідні індекси одночасно.
# Will vector search introduce high latency (slow down my queries) compared to my existing MySQL/full-text search?
На виконанні векторний пошук часто працює швидше за текстовий чи regex-пошук на порівнянних обсягах даних. Звичайні затримки — <200 ms, хоча це залежить від числа кандидатів.
У продакшні при дуже великих наборах даних частіше виникає не затримка, а вартість: структура векторного індексу має вміститися в оперативній пам’яті. Щоб зменшити витрати і пришвидшити роботу, розглядайте vector quantization.
# Conclusion
MongoDB Vector Search — це суттєвий апгрейд в порівнянні з традиційними текстовими запитами: він працює з семантикою, а не з простим підбором ключових слів. Це дозволяє знаходити те, що важко або неможливо знайти звичайними запитами, особливо коли користувач формулює абстрактну або синонімічну за змістом вимогу. Розуміючи намір запиту, векторний пошук витягує найбільш релевантну інформацію — те, що ми називали "unqueryable".
Vector Search доступний у MongoDB, навіть у MongoDB Community Edition. Це дає гнучкість: використовувати MongoDB як основну базу з вбудованим векторним пошуком або як другорядну, масштабовану систему для векторного пошуку. Крім того, MongoDB підтримує повнотекстовий пошук, який можна комбінувати з векторним для гібридного пошуку — функція, від якої багато альтернатив відрізняються.
MongoDB дозволяє обрати архітектуру під ваші потреби, зберігаючи просунуті векторні можливості як рідну функціональність.
Популярні
Як задокументувати кілька API в Laravel за допомогою Scramble
Ви знали, що в одному додатку Laravel можна реалізувати кілька API? У нашій статті ви дізнаєтеся, як за допомогою Scramble легко документувати різні версії API та налаштувати доступ до документації, щоб зробити її публічною або приватною. Читайте далі, щоб дізнатися більше
Використання повнотекстового пошуку в Laravel
Laravel пропонує потужні можливості повнотекстового пошуку за допомогою методів whereFullText та orWhereFullText, що дозволяють здійснювати складні запити до бази даних. Дізнайтеся, як реалізувати ефективний пошук для вашого блогу чи системи управління контентом
Оптимізація запитів до бази даних за допомогою скорочених методів Laravel
Laravel пропонує зручні методи для роботи з датами, які значно спрощують запити до бази даних. Досліджуйте, як ці інтуїтивно зрозумілі функції допомагають створювати чіткі та зрозумілі умови для роботи з часовими даними!